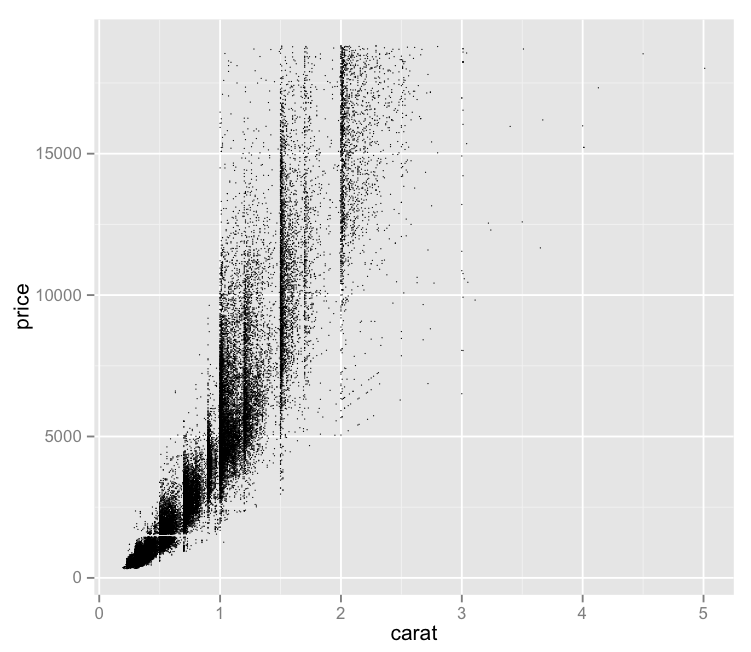
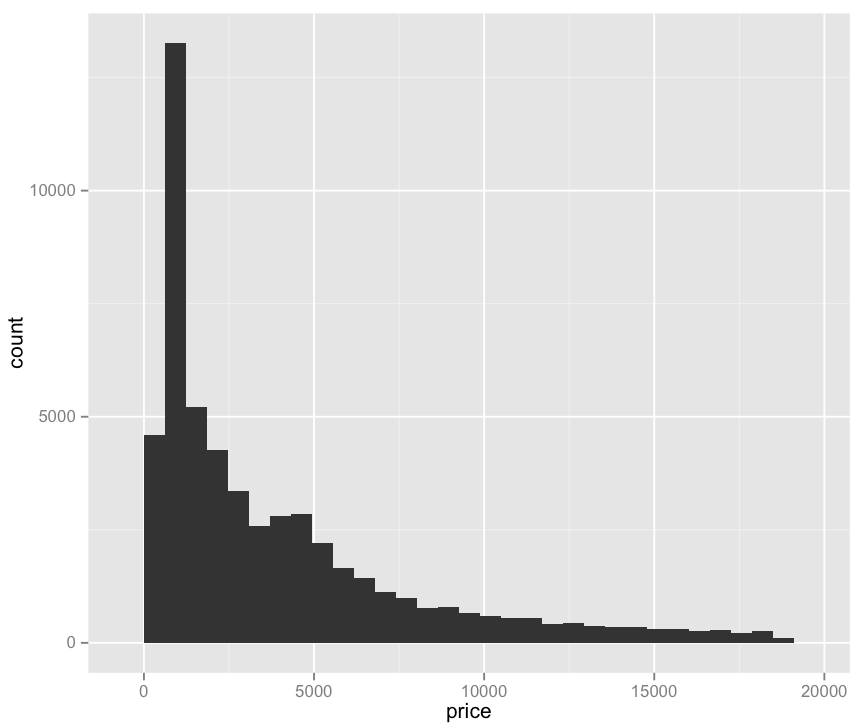
(This Post is part of my 30 day Data Visualization Challenge – you can follow along using the ‘challenge’ tag!)
One of the neat things that ggplot2 can do is take a plot like yesterday’s, and automatically add a third dimension of data – for today I added the column “color,” which indicates the color of the actual diamond measured, as a “color” aesthetic:

Thoughts:
– Now we’re getting somewhere: we can see that yes, more carats tend to be associated with a higher price (with some outliers) but it also looks like certain colors (D,E, F) tend to be lower-priced and/or lower-carat. An interesting question might be to ask which of those factors is more strongly correlated with particular colors.
– We can also see that two of our outliers in this sample are both Js, so there may be interesting things to look into w/r/t that particular color.
– It might be nice to have some sort of drawn line or curve indicating a general trend, as well as maybe a trend per color?
Code:
library(ggplot2) set.seed(1410) dsmall <- diamonds[sample(nrow(diamonds),100),] qplot(carat, price, data=dsmall, size=I(2), color=color)
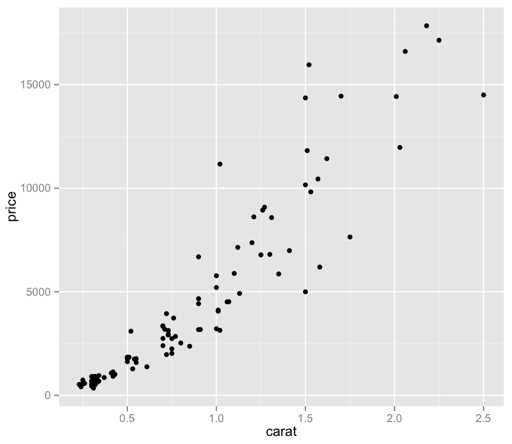 Now we’re cooking! I did have to bump the size of the points back up, as only 100 of those specks were not visually very helpful – but now we have a bit more of a visually intuitive sense of what we’re looking at, without guessing at the larger, imprecise ink blots.
Now we’re cooking! I did have to bump the size of the points back up, as only 100 of those specks were not visually very helpful – but now we have a bit more of a visually intuitive sense of what we’re looking at, without guessing at the larger, imprecise ink blots.