I’m still pretty new to this whole marketing thing: I’ve been a part of Automattic’s marketing efforts for just over a year, and I feel like I’m still learning: the pace of education hasn’t slowed down even a bit.
One of the things that was a real challenge for me was getting to understand the language of the work, especially given our interactions with a number of outside vendors and agencies: the number of acronyms, shorthand and unusual usage of otherwise common words is a huge part of the advertising world, and it serves many purposes.
The import of accessible language is probably something I should save for its own post: I think that, especially in highly interdependent company like Automattic, opaque language, complex jargon, and inscrutable acronyms are more of a hindrance than a help, and in fact likely do us harm, given the way that we, as humans, myself included, want to feel smart, and powerful, and it can be very attractive to nod along rather than ask hard questions.
If you’ve been following this blog for a little while, you know that measurement and the implications of measurement are things that I think about – here’s a piece about metrics generally.
(Here’s a slightly longer one where I take a bit of umbrage, such drama!)
My broad position on metrics is, they’re reductive, necessarily and usefully so, and need to be understood as means rather than as ends.
All that to say, we should also be careful not to treat our metrics as being perhaps more reductive than they really are, or to behave as though what we are measuring is simple, when in fact it is not simple at all.
Taking something complex and making it simple enough to be useful – that’s the essential core of all measurement. Taking something complex and acting like it is something simple is another thing entirely, and a very easy way to increase your overall Lifetime Error Rate.
This brings us to Return on Ad Spend, sometimes shortened to ROAS. Return on Ad Spend can be calculated like this:

…with r being revenue and S being spend. Generally the output is represented either by a ratio like 3:1, where for every dollar you spend on advertising, you get three dollars worth of revenue, or with a percentage – 3:1 would be represented as 300%.
It looks pretty simple. It’s generally referred to as being very simple, or easy, that kind of thing. Which, well, it is, at least on the face of it.
(The rest of this Post is about the sometimes hidden complexities of ROAS. If you want to learn more about using the metric in a tactical way, John at Ignite Visibility has a great write up on how to calculate and break out ROAS, as well as some wrinkles about attribution, which I recommend if that’s what you’re looking for. Here’s a link)
Let’s talk about this metric: ROAS. The name holds a lot of promise, right? Return on Ad Spend: something everyone who spends money on ads wants to learn, the dream of marketers everywhere. How much are we taking back in, for the amount we are putting out?
The trick of ROAS is, we have built in a set of assumptions: specifically, that the numbers we put in represent the whole of each of those categories. The trouble here is that there are only very specific parts of the marketing spend where that is a safe assumption: low-funnel type tactics, especially for e-commerce companies shipping physical products.
In these situations, for these companies, ROAS tends to be a clean metric: you have a very clear picture of where you are spending money, and each transaction has a straightforward, static revenue.
The trick is,
For SaaS companies, ROAS can become much more complicated: imagine your company sells a single product, some type of Helpful Business Software, and it retails for $100 / year. If you run some numbers, you find that you spend on average $50 in ads to get a customer – this looks good, right? We can say we have 200% ROAS and call it a day.
Of course, one of the great advantages of having Data is that we are able to record it, and then see how it changes over time, and try to do the sorts of things in our business that move the needle in our desired direction.
For a SaaS company, two of the metrics that you live or die by are Customer Lifetime Value (sometimes called CLV or LTV) and the dreaded Churn Rate – astute readers will note that these two metrics are inextricably linked. Briefly: LTV is the amount of revenue that your business can expect to make from a given customer, and the dreaded Churn Rate is the expected number of customers (generally at a rate out of 100, represented as a percent, like: “Our Dreaded Churn Rate is a spooky 13%!” )
A saavy SaaS marketing analyst will use the expected lifetime value of a customer in the top of the fraction up there, to determine Return on Ad Spend – for two great reasons. FIRST, because it is more accurate: if you’re looking to determine the total return it makes more sense to use LTV than simply the ticket price. SECOND, because it will make her look better in her reporting.
Consider: for this same sale of our Helpful Business Software, our expected LTV isn’t $100, which is the annual cost of our product, but rather, $200. This doubles our ROAS. This is great news!
(It’s not really news at all though, right? We’re not actually improving either our ads or our product, we just used a more accurate number. Metrics are means!)
One wrinkle, though, is that now we’re not really using that equation above anymore – we’re using something more like:
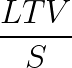
If you’ve ever spent any time trying to calculate your customers’ lifetime value, you know that this has suddenly become a much more complicated metric.
What happens once we start to bring in more complicated ingredients into our ROAS pie here, things like LTV, is that ROAS moves from being a static sort of snapshot into a metric that is much more dependent on other parts of the business to be successful.
In the above example, imagine if your company has had a disastrous year, and your Dreaded Churn Rate has skyrocketed, driving your LTV down to below $100 (due to let’s say sweeping customer refunds and growing customer support costs) – now our ROAS is below 100%, even though literally nothing has changed on the advertising side. In this situation, ROAS becomes a larger aggregate metric, telling us something about the business at large.
This brings to mind a larger question: do we want ROAS to be a heartbeat metric, an indicator of the business overall? Or do we want it to be what it was about a thousand words ago, a simple snapshot of how our advertising efforts are going?
As we move away from direct retail e-commerce businesses into more complex companies, and up what’s called the advertising funnel, ROAS becomes additionally tricky, not because the equation itself becomes more complicated, but because we start to introduce uncertainty, and even worse than that, we introduce unequal uncertainty.
Generally, you know how much you’ve spent. This is true even for less measurable marketing efforts, things like event sponsorships, branding, and so forth. What you decide to include is a little bit of a wrinkle: do you include agency fees? Payroll?
The uncertainty comes into play in the revenue piece, and this is why ROAS as a metric starts to break down as we move up the funnel, because the lower part of your fraction, your spend, stays certain, while the upper part, the revenue, becomes increasingly uncertain, which makes the output more and more difficult to use in a reliable way.
This is a problem that crops up a lot in marketing metrics, and something I’ve been thinking on quite a lot: we often will compare or do arithmetic on numbers which have wildly different underlying levels of base uncertainty, sometimes to our detriment, maybe sometimes to our advantage.
I’ve been working with ROAS quite a lot, and trying to really get my teeth into it, and my brain around its under-the-surface complexity. For most businesses today, ROAS is useful, but it is not as simple as it looks.
This is where I ask you to add something in the comments! What metrics are stuck in your craw this week? Do you think I spend too much time trying to become certain about uncertainty? Let me know!
