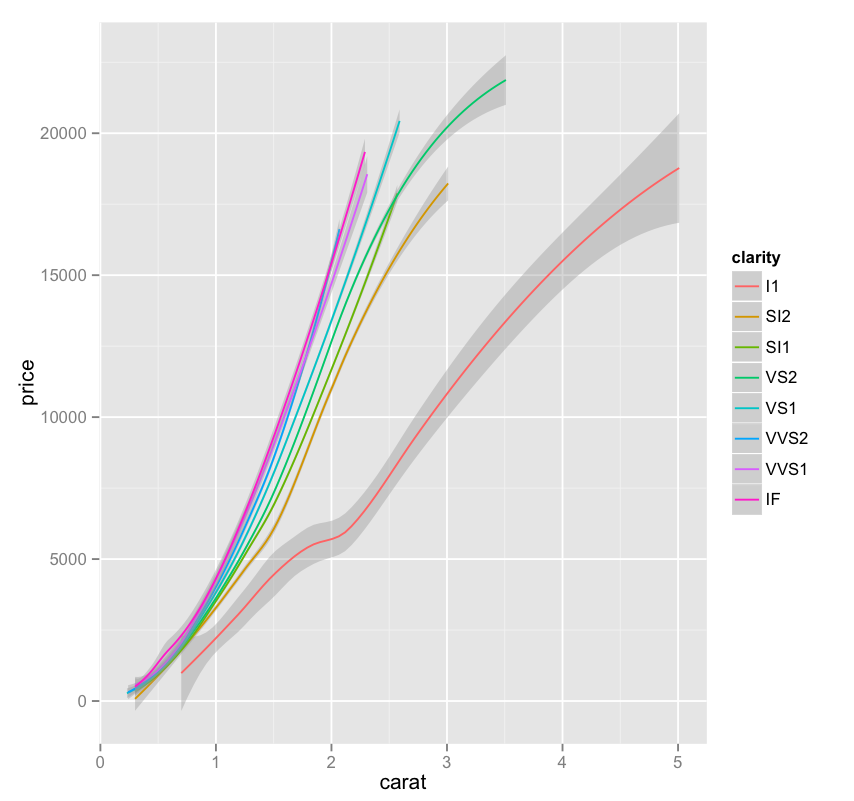
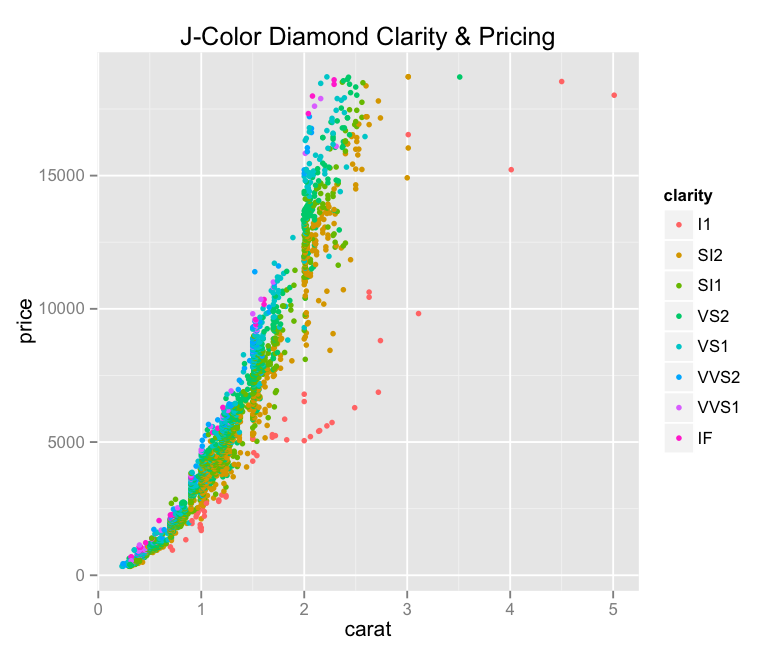
(This Post is part of my 30 day Data Visualization Challenge – you can follow along using the ‘challenge’ tag!)
Testing our earlier hypothesis that the vertical striations in our data were due to a preference for “whole” carat numbers – or at least more readable numbers, we can look at a single-variable histogram:
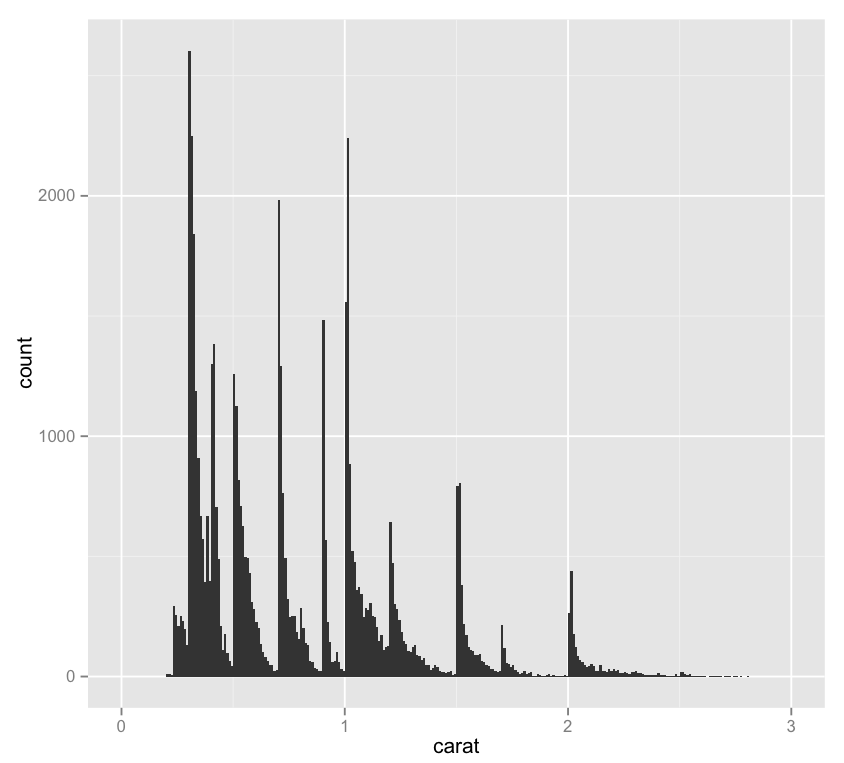
Thoughts:
– One interesting thing about this chart is the importance of binwidth, which sets the resolution of the data in a histogram – for instance, here’s this same chart with a binwidth of .15 rather than .01. It loses a lot of the utility of the chart above!
– It might be interesting to display a second variable here in a way other than on the y-axis – as a color maybe.
Code:
library(ggplot2) qplot(carat, data=diamonds, geom="histogram", binwidth=.01, xlim=c(0,3))