In the Toyota Production System (TPS) and its ongoing adherence in Western companies (usually called Lean, often mixed in with Six Sigma processes), one of the ways that we are able to reduce waste is moving from batch production to single piece flow, or continuous flow.
The opposing styles here are characterized like so: if Process Zoidberg requires you to perform actions A, B, and C, and you have to perform 100 Zoidbergs, batch production would suggest you do _all_ of your As, then _all_ of your Bs, then _all_ of your Cs. Continuous flow would suggest that you do A, then B, then C, one hundred times.
When we think about supporting a customer base, we can visualize each customer experience as a finished product, with each of their questions or friction points as a discrete component. We could extend this metaphor to the entire product development life cycle, but for the scope of this article, let’s focus on the post-launch product support, by (mostly) dedicated support staff.
Thinking of customer support using the well-trod ground of manufacturing, we can start to use insights that have already provided serious gains for other industries – it can also help us to explain data that we already have, or better understand or phrase our support for new experiments and learning opportunities.
When we consider traditional email support from the side of the customer, a customer sends in a request, they wait, the support staff replies, wait, customer replies again, with a new question or concern, they wait, and so on. If you asked the customer, it looks a lot like an (especially slow) continuous flow model.
From the side of the support staff, we see a different picture: they reply to customer requests as they come in, working with many customers at many different points in that particular customers’ process. Rather than working with one customer from the beginning, through all of their questions, to the conclusion, they move from question to question.
When we consider live chat support, it looks to be much more in line with the continuous flow model – as a customer arrives, they are picked up by a support team member, and they are moved through each of their questions in turn, to the point of completion.
It would be interesting to see some data on how these two processes look side-by-side, especially in terms of efficiency of production – which here would mean customer-questions-answered. I acknowledge that it might be tricky to suss out exactly when a question is answered, especially in an automated way. Tricky, but interesting.
My hunch would be that providing support in the continuous-flow model would gain similar efficiency gains to the adoption of that model in other industries, but, that’s just a hunch.

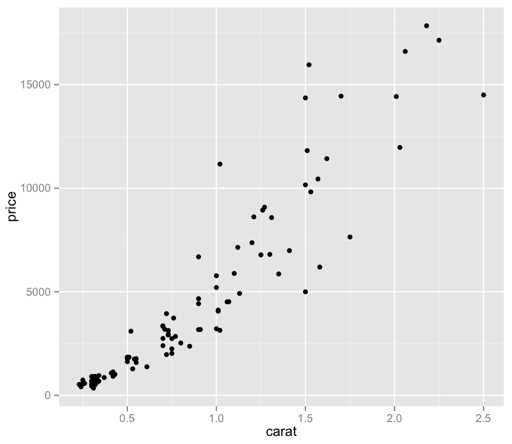 Now we’re cooking! I did have to bump the size of the points back up, as only 100 of those specks were not visually very helpful – but now we have a bit more of a visually intuitive sense of what we’re looking at, without guessing at the larger, imprecise ink blots.
Now we’re cooking! I did have to bump the size of the points back up, as only 100 of those specks were not visually very helpful – but now we have a bit more of a visually intuitive sense of what we’re looking at, without guessing at the larger, imprecise ink blots.