(This Post is part of my 30 day Data Visualization Challenge – you can follow along using the ‘challenge’ tag!)
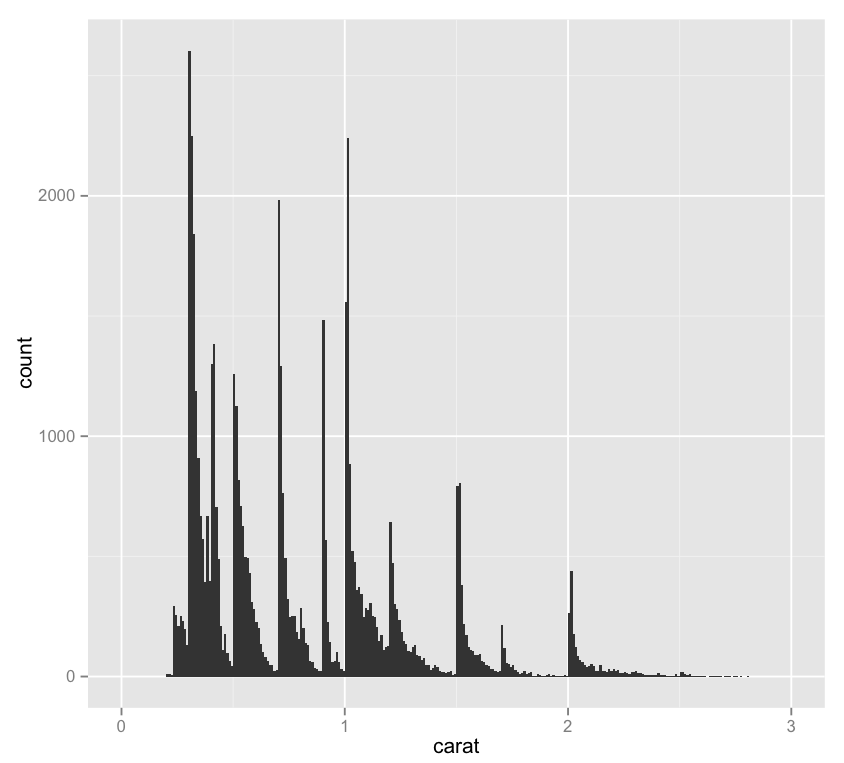
In playing a bit more with the qplot geoms call, I spent some time with the “jitters” geom, which has nothing to do with coffee, as it turns out. Jittering is a neat method to fight against the same sort of dot density that we saw earlier in the challenge – it creates a larger space for points to be plotted, which makes a visualization more readable. Here’s this same visualization without the jittering.

Thoughts:
– The more I do this, the more I realize I don’t know about diamonds.
– The more I do this, the more I realize I don’t yet understand about R and visualizing data. It’s exciting!
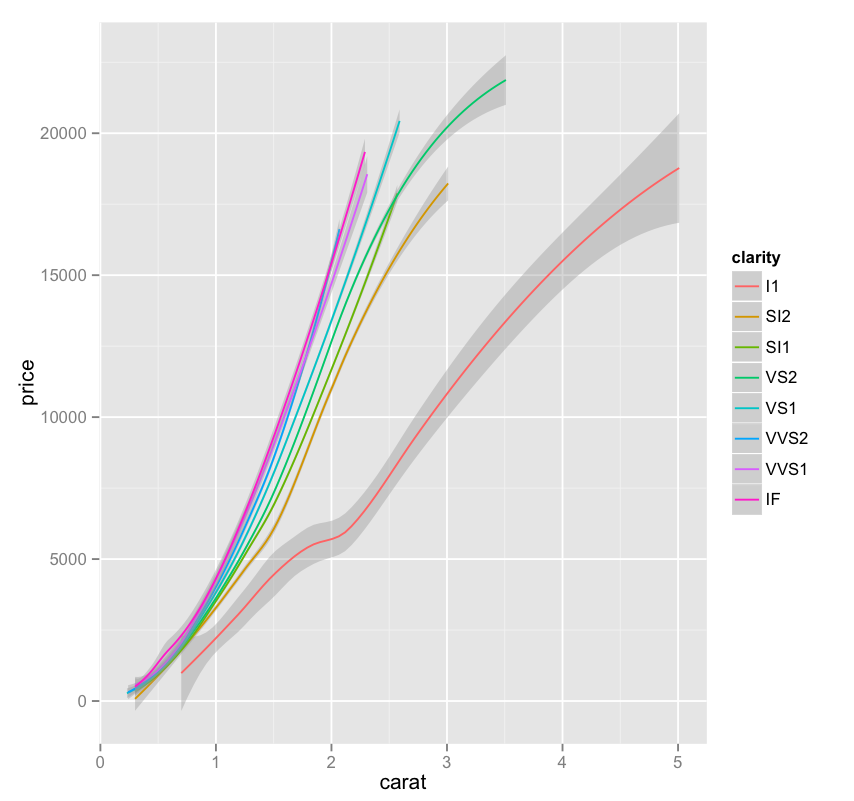
– There’s a consistent pattern to the clarity layers that we see, repeating what looks like 3 times, yellow, green, blue, pink, and then again, and then a third time, with pink sort of stretching skyward. What’s that about?
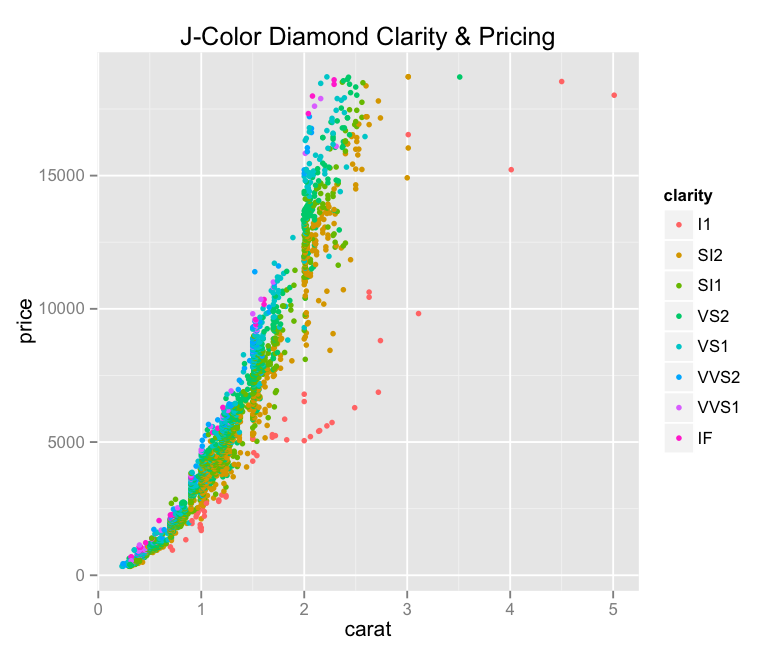
– The “J” color continues to be interesting to me – why is it so jumbled up when the others seem to be at least somewhat orderly? It also reaffirms our previous findings, where we noticed that “J” diamonds seemed to be outliers (in a bad way) on the price vs. carat chart.
Code:
library(ggplot2)
qplot(color, price/carat, color=clarity, data=diamonds, geom="jitter")